What is RAID?
RAID stands for Redundant Array of Inexpensive (Independent) Disks. Data is distributed across the drives in one of several ways called “RAID levels”, depending on what level of redundancy and performance is required.
RAID Concepts
- Striping
- Mirroring
- Parity or Error Correction
- Hardware or Software RAID
RAID Levels
0,1,5 and 10 are the most commonly used RAID Levels
- RAID 0
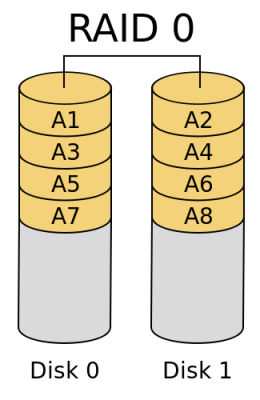
RAID 0 (block-level striping without parity or mirroring) has no (or zero) redundancy. It provides improved performance and additional storage but no fault tolerance. Hence simple stripe sets are normally referred to as RAID 0. Any drive failure destroys the array, and the likelihood of failure increases with more drives in the array. A single drive failure destroys the entire array because when data is written to a RAID 0 volume, the data is broken into fragments called blocks. The number of blocks is dictated by the stripe size, which is a configuration parameter of the array. The blocks are written to their respective drives simultaneously on the same sector. This allows smaller sections of the entire chunk of data to be read off each drive in parallel, increasing bandwidth. RAID 0 does not implement error checking, so any read error is uncorrectable. More drives in the array means higher bandwidth, but greater risk of data loss.
- RAID 1
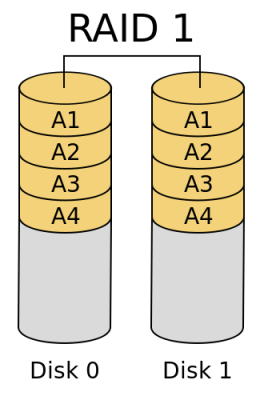
In RAID 1 (mirroring without parity or striping), data is written identically to two drives, thereby producing a “mirrored set”; the read request is serviced by either of the two drives containing the requested data, whichever one involves least seek time plus rotational latency. Similarly, a write request updates the stripes of both drives. The write performance depends on the slower of the two writes (i.e., the one that involves larger seek time and rotational latency); at least two drives are required to constitute such an array. While more constituent drives may be employed, many implementations deal with a maximum of only two. The array continues to operate as long as at least one drive is functioning. With appropriate operating system support, there can be increased read performance as data can be read off any of the drives in the array, and only a minimal write performance reduction; implementing RAID 1 with a separate controller for each drive in order to perform simultaneous reads (and writes) is sometimes called “multiplexing” (or “duplexing” when there are only two drives)
When the workload is write intensive you want to use RAID 1 or RAID 1+0
- RAID 5
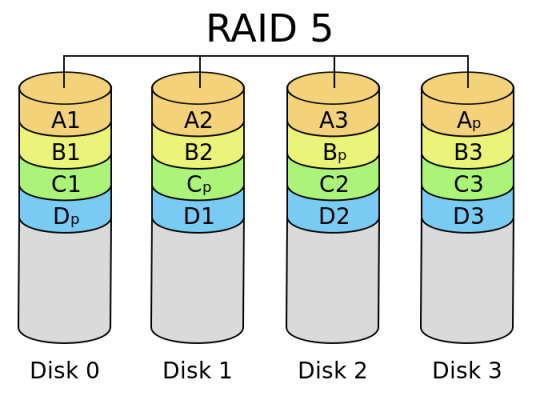
RAID 5 (block-level striping with distributed parity) distributes parity along with the data and requires all drives but one to be present to operate; the array is not destroyed by a single drive failure. Upon drive failure, any subsequent reads can be calculated from the distributed parity such that the drive failure is masked from the end user. However, a single drive failure results in reduced performance of the entire array until the failed drive has been replaced and the associated data rebuilt, because each block of the failed disk needs to be reconstructed by reading all other disks i.e. the parity and other data blocks of a RAID stripe. RAID 5 requires at least three disks. Best cost effective option providing both performance and redundancy. Use this for DB that is heavily read oriented. Write operations will be dependent on the RAID Controller used due to the need to calculate the parity data and write it across all the disks
When your workloads are read intensive it is best to use RAID 5 or RAID 6 and especially for web servers where most of the transactions are read
Don’t use RAID 5 for heavy write environments such as Database servers
- RAID 10 or 1+0 (Stripe of Mirrors)
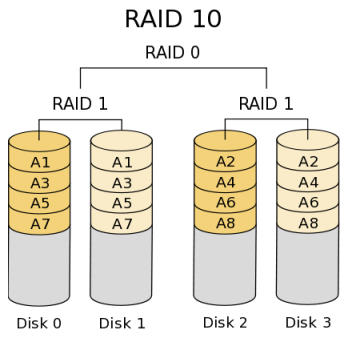
In RAID 10 (mirroring and striping), data is written in stripes across primary disks that have been mirrored to the secondary disks. A typical RAID 10 configuration consists of four drives, two for striping and two for mirroring. A RAID 10 configuration takes the best concepts of RAID 0 and RAID 1, and combines them to provide better performance along with the reliability of parity without actually having parity as with RAID 5 and RAID 6. RAID 10 is often referred to as RAID 1+0 (mirrored+striped) This is the recommended option for any mission critical applications (especially databases) and requires a minimum of 4 disks. Performance on both RAID 10 and RAID 01 will be the same.
- RAID 01 (Mirror of Stripes)
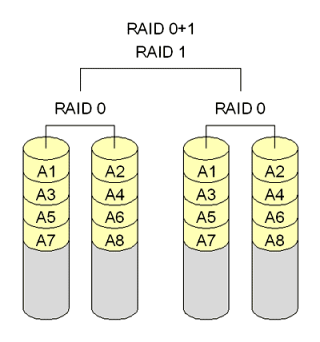
RAID 01 is also called as RAID 0+1. It requires a minimum of 3 disks. But in most cases this will be implemented as minimum of 4 disks. Imagine two groups of 3 disks. For example, if you have total of 6 disks, create 2 groups. Group 1 has 3 disks and Group 2 has 3 disks.
Within the group, the data is striped. i.e In the Group 1 which contains three disks, the 1st block will be written to 1st disk, 2nd block to 2nd disk, and the 3rd block to 3rd disk. So, block A is written to Disk 1, block B to Disk 2, block C to Disk 3.
Across the group, the data is mirrored. i.e The Group 1 and Group 2 will look exactly the same. i.e Disk 1 is mirrored to Disk 4, Disk 2 to Disk 5, Disk 3 to Disk 6. This is why it is called “mirror of stripes”. i.e the disks within the groups are striped. But, the groups are mirrored. Performance on both RAID 10 and RAID 01 will be the same.
- RAID 2
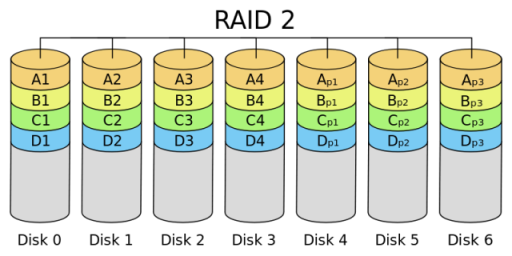
In RAID 2 (bit-level striping with dedicated Hamming-code parity), all disk spindle rotation is synchronized, and data is striped such that each sequential bit is on a different drive. Hamming-code parity is calculated across corresponding bits and stored on at least one parity drive. This theoretical RAID level is not used in practice. You need two groups of disks. One group of disks are used to write the data, another group is used to write the error correction codes. This is not used anymore. This is expensive and implementing it in a RAID controller is complex, and ECC is redundant now-a-days, as the hard disk themselves can do this themselves
- RAID 3
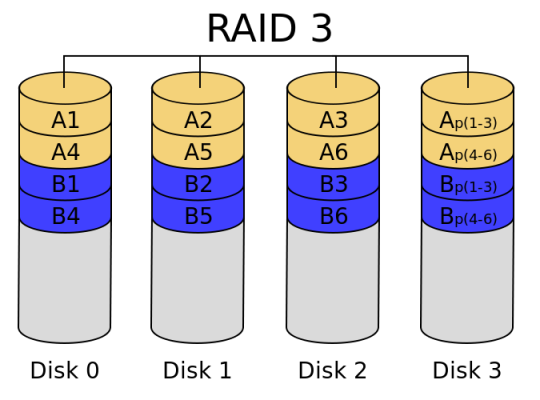
In RAID 3 (byte-level striping with dedicated parity), all disk spindle rotation is synchronized, and data is striped so each sequential byte is on a different drive. Parity is calculated across corresponding bytes and stored on a dedicated parity drive. Although implementations exist, RAID 3 is not commonly used in practice. Sequential read and write will have good performance. Random read and write will have worst performance.
- RAID 4
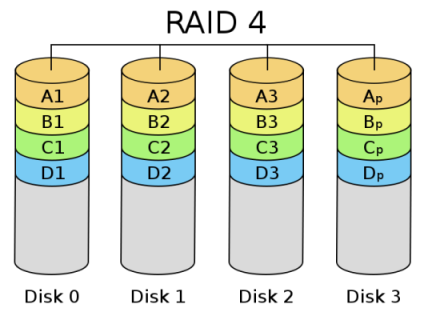
RAID 4 (block-level striping with dedicated parity) is identical to RAID 5 (see below), but confines all parity data to a single drive. In this setup, files may be distributed between multiple drives. Each drive operates independently, allowing I/O requests to be performed in parallel. However, the use of a dedicated parity drive could create a performance bottleneck; because the parity data must be written to a single, dedicated parity drive for each block of non-parity data, the overall write performance may depend a great deal on the performance of this parity drive.
- RAID 6
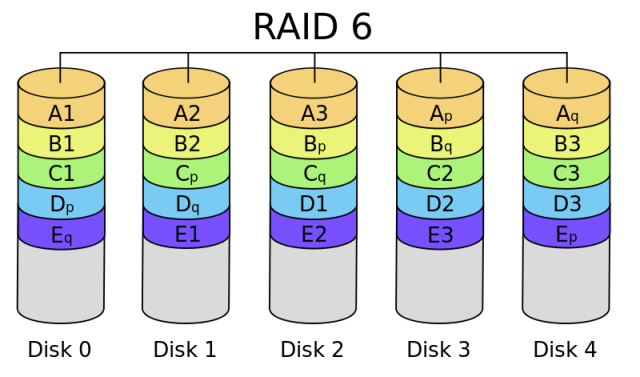
RAID 6 (block-level striping with double distributed parity) provides fault tolerance of two drive failures; the array continues to operate with up to two failed drives. This makes larger RAID groups more practical, especially for high-availability systems. This becomes increasingly important as large-capacity drives lengthen the time needed to recover from the failure of a single drive. Single-parity RAID levels are as vulnerable to data loss as a RAID 0 array until the failed drive is replaced and its data rebuilt; the larger the drive, the longer the rebuild takes. Double parity gives additional time to rebuild the array without the data being at risk if a single additional drive fails before the rebuild is complete. Like RAID 5, a single drive failure results in reduced performance of the entire array until the failed drive has been replaced and the associated data rebuilt.
Don’t use for high random write workloads
What is Parity?
Parity data is used by some RAID levels to achieve redundancy. If a drive in the array fails, remaining data on the other drives can be combined with the parity data (using the Boolean XOR function) to reconstruct the missing data.
For example, suppose two drives in a three-drive RAID 5 array contained the following data:
Drive 1: 01101101
Drive 2: 11010100
To calculate parity data for the two drives, an XOR is performed on their data:
01101101
XOR 11010100
_____________
10111001
The resulting parity data, 10111001, is then stored on Drive 3.
Should any of the three drives fail, the contents of the failed drive can be reconstructed on a replacement drive by subjecting the data from the remaining drives to the same XOR operation. If Drive 2 were to fail, its data could be rebuilt using the XOR results of the contents of the two remaining drives, Drive 1 and Drive 3:
Drive 1: 01101101
Drive 3: 10111001
as follows:
10111001
XOR 01101101
_____________
11010100
The result of that XOR calculation yields Drive 2’s contents. 11010100 is then stored on Drive 2, fully repairing the array. This same XOR concept applies similarly to larger arrays, using any number of disks. In the case of a RAID 3 array of 12 drives, 11 drives participate in the XOR calculation shown above and yield a value that is then stored on the dedicated parity drive.
RAID Level Comparison
Interesting Link
http://www.miracleas.com/BAARF/RAID5_versus_RAID10.txt










