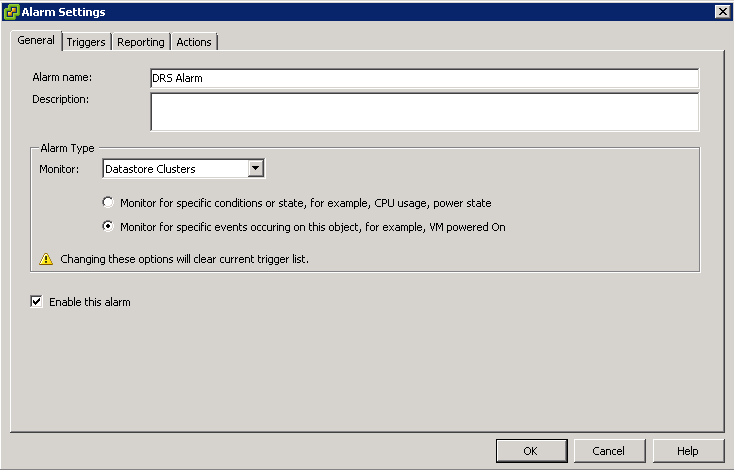
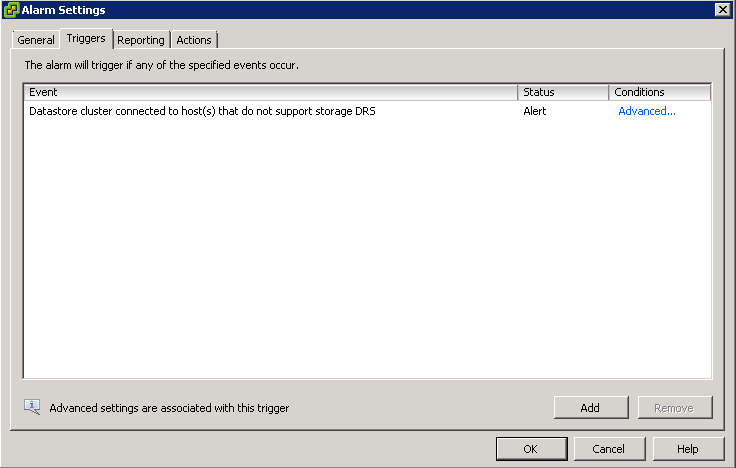
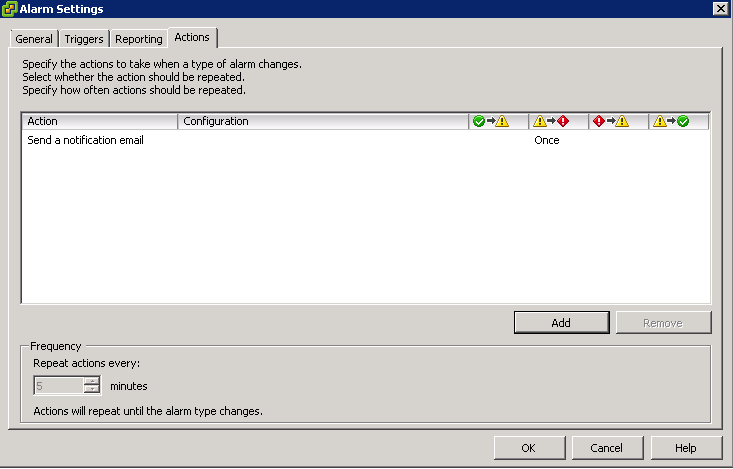
What is DRS?
A DRS cluster is a collection of ESXi hosts and associated virtual machines with shared resources and a shared interface. Before you can obtain the benefits of cluster-level resource management you must create a DRS cluster.
When you add a host to a DRS cluster, the host’s resources become part of the cluster’s resources. In addition to this aggregation of resources, with a DRS cluster you can support cluster-wide resource pools and enforce cluster-level resource allocation policies. The following cluster-level resource management capabilities are also available.
DRS must use Shared Storage and a vMotion network
The distribution and usage of CPU and memory resources for all hosts and virtual machines in the cluster are continuously monitored. DRS compares these metrics to an ideal resource utilization given the attributes of the cluster’s resource pools and virtual machines, the current demand, and the imbalance target. It then performs (or recommends) virtual machine migrations accordingly. When you first power on a virtual machine in the cluster, DRS attempts to maintain proper load balancing by either placing the virtual machine on an appropriate host or making a recommendation.
When the vSphere Distributed Power Management (DPM) feature is enabled, DRS compares cluster- and host-level capacity to the demands of the cluster’s virtual machines, including recent historical demand. It places (or recommends placing) hosts in standby power mode if sufficient excess capacity is found or powering on hosts if capacity is needed. Depending on the resulting host power state recommendations, virtual machines might need to be migrated to and from the hosts as well.
You can control the placement of virtual machines on hosts within a cluster, by
assigning affinity rules.
DRS, EVC and FT
Depending on whether or not Enhanced vMotion Compatibility (EVC) is enabled, DRS behaves differently when you use vSphere Fault Tolerance (vSphere FT) virtual machines in your cluster.

Migration Recommendations
The system supplies as many recommendations as necessary to enforce rules and balance the resources of the cluster. Each recommendation includes the virtual machine to be moved, current (source) host and destination host, and a reason for the recommendation. The reason can be one of the following:
- Balance average CPU loads or reservations
- Balance average memory loads or reservations
- Satisfy resource pool reservations
- Satisfy an affinity rule.
- Host is entering maintenance mode or standby mode.
Note: If you are using the vSphere Distributed Power Management (DPM) feature, in addition to migration recommendations, DRS provides host power state recommendations
Using DRS Affinity Rules
You can control the placement of virtual machines on hosts within a cluster by using affinity rules. You can create two types of rules.
Used to specify affinity or anti-affinity between a group of virtual machines and a group of hosts. An affinity rule specifies that the members of a selected virtual machine DRS group can or must run on the members of a specific host DRS group. An anti-affinity rule specifies that the members of a selected virtual machine DRS group cannot run on the members of a specific host DRS group.
Used to specify affinity or anti-affinity between individual virtual machines. A rule specifying affinity causes DRS to try to keep the specified virtual machines together on the same host, for example, for performance reasons. With an anti-affinity rule, DRS tries to keep the specified virtual machines apart, for example, so that when a problem occurs with one host, you do not lose both virtual machines. When you add or edit an affinity rule, and the cluster’s current state is in violation of the rule, the system continues to operate and tries to correct the violation. For manual and partially automated DRS clusters, migration recommendations based on rule fulfillment and load balancing are presented for approval. You are not required to fulfill the rules, but the corresponding recommendations remain until the rules are fulfilled.
To check whether any enabled affinity rules are being violated and cannot be corrected by DRS, select the cluster’s DRS tab and click Faults. Any rule currently being violated has a corresponding fault on this page.
Read the fault to determine why DRS is not able to satisfy the particular rule. Rules violations also produce a log event.
DRS Automation Levels
Someone at my work asked me about these levels and wanted an explanation for the Aggressive Level. He said he envisaged machines continually moving around in a state of perpetual motion. Lets find out!
Just as a note, you access DRS Automation Level Settings by right clicking on the cluster and selecting Edit Settings, then selecting VMware DRS
There are 3 settings
- Manual – vCenter will suggest migration recommendations for virtual machines
- Partially Automated – Virtual machines will be placed onto hosts at power on and vCenter will suggest migration recommendations for virtual machines
- Fully Automated – Virtual machines will be automatically places on to hosts when powered on and will be automatically migrated from one host to another to optimize resource usage
For Fully Automated there is a slider called Migration threshold

You can move the slider to use one of the five levels
- Level 1 – Apply only five-star recommendations. Includes recommendations that must be followed to satisfy cluster constraints, such as affinity rules and host maintenance. This level indicates a mandatory move, required to satisfy an affinity rule or evacuate a host that is entering maintenance mode.
- Level 2 – Apply recommendations with four or more stars. Includes Level 1 plus recommendations that promise a significant improvement in the cluster’s load balance.
- Level 3 – Apply recommendations with three or more stars. Includes Level 1 and 2 plus recommendations that promise a good improvement in the cluster’s load balance.
- Level 4 – Apply recommendations with two or more stars. Includes Level 1-3 plus recommendations that promise a moderate improvement in the cluster’s load balance.
- Level 5 – Apply all recommendations. Includes Level 1-4 plus recommendations that promise a slight improvement in the cluster’s load balance.
Some interesting facts
- DRS has a threshold of up to 60 vMotion events per hour
- It will check for imbalances in the cluster once every five minutes
vCenter Console
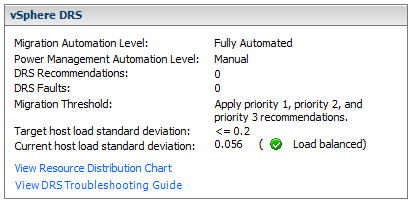
When the Current host load standard deviation exceeds the target host load standard deviation, DRS will make recommendations and take action based on the automation level and migration threshold
The target host load standard deviation is derived from the migration threshold setting. A load is considered imbalanced as long as the current value exceeds the migration threshold.
Each host has a host load metric based upon the CPU and memory resources in use. It is described as the sum of expected virtual machine loads divided by the capacity of the host. The LoadImbalanceMetric also known as the current host load standard deviation is the standard deviation (average of averages) of all host load metrics in a cluster.
DRS decides what virtual machines are migrated based on simulating a move and recalculating the current host load standard deviation and making a recommendation. As part of this simulation, a cost benefit and risk analysis is performed to determine best placement. DRS will continue to perform simulations and will make recommendations as long as the current host load exceeds the target host load.
Properly size virtual machine automation levels based on Application Requirements
- When a virtual machine is powered on, DRS is responsible for performing initial placement. During initial placement, DRS considers the “worst case scenario” for a VM. For example, when a new server that has been overspec’d gets powered on, DRS will actively attempt to identify a host that can guarantee that CPU and RAM to the VM. This is due to the fact that historical resource utilization statistics for the VM are unavailable. If DRS cannot find a cluster host able to accommodate the VM, it will be forced to “defragment” the cluster by moving other VMs around to account for the one being powered on. As such, VMs should be be sized based on their current workload.
- When performing an assessment of a physical environment as part of a vSphere migration, an administrator should leverage the resource utilization data from VMware Capacity Planner in allocating resources to VMs.
- Do not set VM reservations too high as this can affect DRS Balancing DRS might not have excess resources to move VMs around
- Group Virtual Machines for a multi-tier service into a Resource Pool
- Don’t forget to calculate memory overhead when sizing VMs into clusters
- Use Resource Settings such as Shares, Limits and Reservations only when necessary
- You might want to keep VMs on the same host if they are part of a tiered application that runs on multiple VMs, such as a web, application, or database server.
- You might want to keep VMs on different hosts for servers that are clustered or redundant, such as Active Directory (AD), DNS, or web servers, so that a single ESX failure does not affect both servers at the same time. Doing this ensures that at least one will stay up and remain available while the other recovers from a host failure.
- You might want to separate servers that have high I/O workloads so that you do not overburden a specific host with too many high-workload servers.
- Keep servers like vCenter, the vCenter DB and Domain Controllers as a high priority